C2LEVA: Toward Comprehensive and Contamination-Free Language Model EVAluation
'%20fill='%237c7469'/%3e%3cpath%20d='M539.233,255.154c2.656,0,4.074,1.416,4.074,4.074v34.007h10.1c2.746,0,4.074,1.329,4.074,4.074s-1.328,4.074-4.074,4.074H524.8c-2.656,0-4.074-1.328-4.074-4.074s1.418-4.074,4.074-4.074h10.362V263.3h-8.533c-2.744,0-4.073-1.329-4.073-4.074,0-2.658,1.329-4.074,4.073-4.074Zm4.22-17.615a5.859,5.859,0,1,1-5.819-5.819A5.9,5.9,0,0,1,543.453,237.539Z'%20transform='translate(-358.165%20-222.27)'%20fill='%237c7469'/%3e%3cpath%20d='M605.143,259.228a4.589,4.589,0,0,1-.267,1.594L590,298.9a3.722,3.722,0,0,1-3.721,2.48h-5.933a3.689,3.689,0,0,1-3.808-2.48l-15.055-38.081a3.23,3.23,0,0,1-.355-1.594,4.084,4.084,0,0,1,4.164-4.074,3.8,3.8,0,0,1,3.718,2.656l14.348,36.134,13.9-36.134a3.8,3.8,0,0,1,3.72-2.656A4.084,4.084,0,0,1,605.143,259.228Z'%20transform='translate(-358.165%20-222.27)'%20fill='%237c7469'/%3e%3cpath%20d='M486.149,277.877l-32.741,38.852c-1.286,1.372-2.084,3.777-1.365,5.5a4.705,4.705,0,0,0,4.4,2.914,4.191,4.191,0,0,0,3.16-1.563l40.191-42.714a4.417,4.417,0,0,0,.042-6.042Z'%20transform='translate(-358.165%20-222.27)'%20fill='%23aa142d'/%3e%3cpath%20d='M486.149,277.877l31.187-38.268c1.492-1.989,2.2-3.03,1.492-4.723a5.142,5.142,0,0,0-4.481-3.161h0a4.024,4.024,0,0,0-3.008,1.108L472.711,274.6a4.769,4.769,0,0,0,.015,6.53L520.512,332.2a3.913,3.913,0,0,0,3.137,1.192,4.394,4.394,0,0,0,4.027-2.818c.719-1.727-.076-3.438-1.4-5.23l-40.124-47.464'%20transform='translate(-358.165%20-222.27)'%20fill='%237c7469'/%3e%3cpath%20d='M499.833,274.828,453.169,224.4s-1.713-2.08-3.524-2.124a4.607,4.607,0,0,0-4.338,2.788c-.705,1.692-.2,2.88,1.349,5.1l40.093,48.422'%20transform='translate(-358.165%20-222.27)'%20fill='%23aa142d'/%3e%3cpath%20d='M390.61,255.154c5.018,0,8.206,3.312,8.206,8.4v37.831H363.308a4.813,4.813,0,0,1-5.143-4.929V283.427a8.256,8.256,0,0,1,7-8.148l25.507-3.572v-8.4H362.306a4.014,4.014,0,0,1-4.141-4.074c0-2.87,2.143-4.074,4.355-4.074Zm.059,38.081V279.942l-24.354,3.4v9.9Z'%20transform='translate(-358.165%20-222.27)'%20fill='%237c7469'/%3e%3c/svg%3e) Paper
Paper🎯 Overview
TL;DR: We release C2LEVA, a comprehensive bilingual benchmark with systematic contamination prevention. Large-scale evaluation on 15 large language models demonstrates the effectiveness of C2LEVA.
Recent advances in large language models (LLMs) have shown significant promise, yet their evaluation raises concerns, particularly regarding data contamination due to the lack of access to proprietary training data.
To address this issue, we present C2LEVA, which offers (1) a holistic bilingual (Chinese and English) benchmark encompassing 22 tasks, each targeting a specific application or ability of LLMs; (2) A trustworthy assessment due to our contamination-free tasks, ensured by a systematic contamination prevention strategy that fully automates test data renewal and enforces data protection during benchmark data release.
Our large-scale evaluation of 15 open-source and proprietary models shows that C2LEVA achieves a 94.8% correlation with Chatbot Arena's overall rankings, while being fully transparent and reproducible.
💡 Highlights
1. Systematic Contamination Prevention.
C2LEVA systematically prevents data contamination from both the passive and active perspectives: C2LEVA addresses repurposing attacks through contamination detection and data scarcity via data augmentation; C2LEVA implements data protection techniques during benchmark release, prolonging the effectiveness of the passive solution.
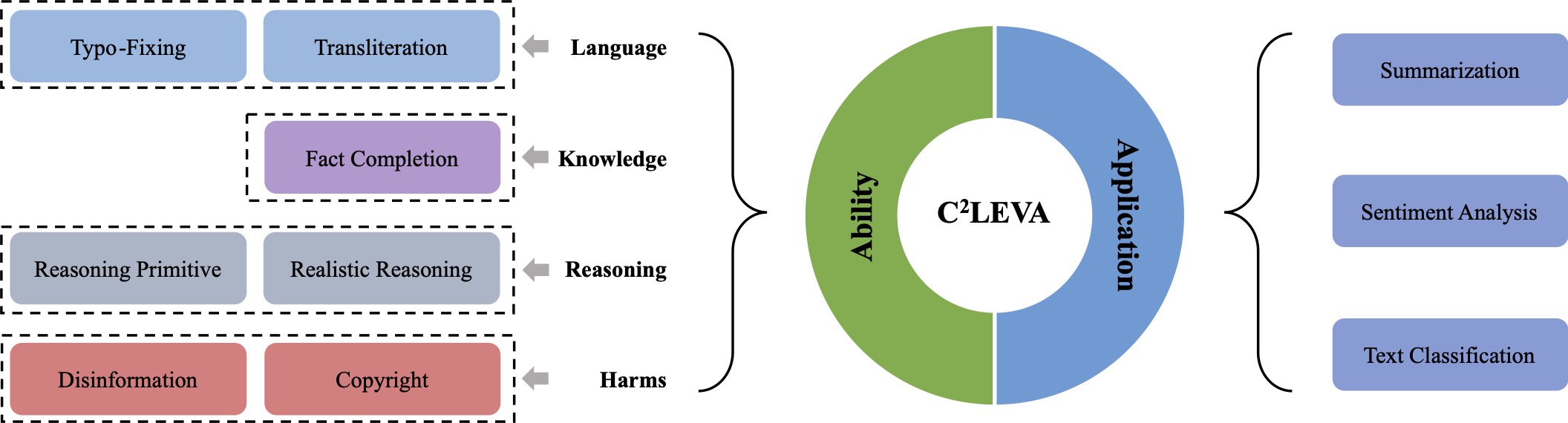
2. A Comprehensive and Contamination-Free Task Taxonomy.
With contamination prevention techniques applied, C2LEVA contains 22 tasks, in English and Simplified Chinese, for application assessment and ability evaluation.
3. Large-Scale Evaluation Experiments.
C2LEVA evaluates 15 open-source and proprietary LLMs. The leaderboard will be continuously maintained and updated.
🛠️ Framework
Our system consists of two stages: data collection and prevention:
- In the data collection, we use a set of crawlers and simulators to gather or synthesize high-quality data and store it into the database.
- To generate a test set, we apply a series of passive prevention techniques to raw data sampled from the database, followed by the active prevention method.
🔎 Task Taxonomy & Examples
📊 Leaderboard
English Results
Data Version: 2024-07-04
🖊️ Data & Citation
Below are the links to request the past versions of C2LEVA test sets.
Please cite our paper if you find our work helpful:
@misc{li2023cleva,
title={CLEVA: Chinese Language Models EVAluation Platform},
author={Yanyang Li and Jianqiao Zhao and Duo Zheng and Zi-Yuan Hu and Zhi Chen and Xiaohui Su and Yongfeng Huang and Shijia Huang and Dahua Lin and Michael R. Lyu and Liwei Wang},
year={2023},
eprint={2308.04813},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2308.04813},
}
@misc{li2024c2leva,
title={C$^2$LEVA: Toward Comprehensive and Contamination-Free Language Model Evaluation},
author={Yanyang Li and Tin Long Wong and Cheung To Hung and Jianqiao Zhao and Duo Zheng and Ka Wai Liu and Michael R. Lyu and Liwei Wang},
year={2024},
eprint={2412.04947},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.04947},
}